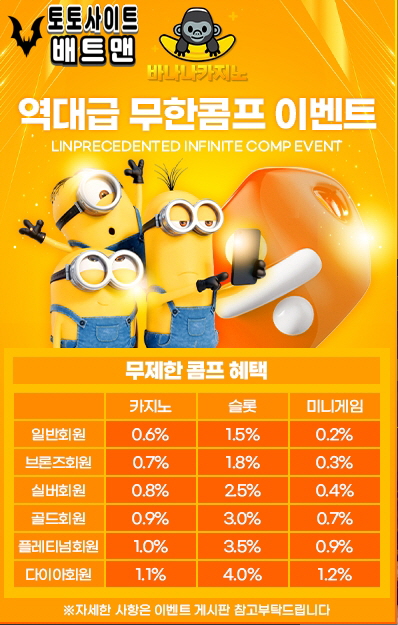
저희 배트맨은 바나나 토토 와의 전략적 제휴를 통해 회원 여러분의 안전을 최우선으로 보장하기 위해 1억 원의 보증금을 확보했습니다. 이 보증금은 회원님들이 안심하고 바나나 토토의 다양한 서비스를 이용하실 수 있도록 든든한 기반이 됩니다. 보증금을 통해 여러분이 게임을 즐기는 동안 발생할 수 있는 모든 불확실성에 대비하고 있으며, 안전하고 신뢰할 수 있는 환경을 제공하기 위해 최선을 다하고 있습니다.
배트맨 전용 코드를 사용하여 가입하신 모든 회원님께는 어떠한 문제 상황이 발생하더라도 100% 책임을 지고 문제를 해결해 드릴 것을 약속드립니다. 특히, 문제로 인해 발생할 수 있는 모든 손해는 보증금에서 전액 환불해 드리며, 회원 여러분이 언제나 안심하고 서비스를 이용하실 수 있도록 보장하고 있습니다. 저희는 회원 여러분의 신뢰를 지키기 위해 최선을 다하고 있으며, 이러한 약속은 배트맨의 핵심 가치 중 하나입니다.
바나나 토토는 사용자들의 안전을 가장 중요하게 생각하며, 이를 위해 지속적으로 시스템을 강화하고 있습니다. 첨단 보안 기술을 도입하고, 데이터를 보호하기 위한 최신 기술을 적용함으로써, 사용자 여러분이 게임을 즐기는 동안 불안함을 느끼지 않도록 최선을 다하고 있습니다. 다양한 이벤트와 혜택을 통해 사용자들이 더욱 즐겁고 풍성한 경험을 할 수 있도록 노력하고 있습니다. 이러한 모든 노력은 사용자 여러분이 안심하고 게임을 즐길 수 있는 환경을 조성하기 위한 것입니다.
대한민국에서 가장 신뢰받는 검증 회사로 인정받고 있는 배트맨은 엄격한 기준과 철저한 검토 과정을 통해 바나나 토토의 안전성을 확인했습니다. 이러한 검증은 단순한 형식적인 절차가 아니라, 회원 여러분의 안전을 위한 중요한 과정이며, 저희는 바나나 토토를 자신 있게 추천드릴 수 있습니다. 배트맨은 바나나 토토와의 협력을 통해 더욱 안전하고 신뢰할 수 있는 토토사이트를 제공하기 위해 지속적으로 노력하고 있으며, 회원님들께 최고의 서비스를 제공하는 것을 목표로 하고 있습니다.
이제 배트맨의 전용 코드를 통해 바나나 토토의 안전하고 즐거운 서비스를 직접 경험해보세요. 저희 배트맨은 언제나 회원 여러분의 만족과 안전을 최우선으로 생각하며, 여러분 곁에서 든든한 파트너로서 함께 하겠습니다. 신뢰할 수 있는 환경에서 마음껏 즐기실 수 있도록, 배트맨은 여러분의 곁에서 항상 지켜드릴 것을 약속드립니다. 감사합니다.
바나나 토토는 국내에서 인정받은 최고의 검증 기업인 배트맨에 의해 철저한 기준과 정교한 절차를 통해 인증된, 최상위 수준의 안전한 배팅 플랫폼입니다. 배트맨은 오랜 기간 축적된 경험과 고도화된 기술력을 바탕으로 한 독특하고 체계적인 시스템을 구축하여, 사이트의 신뢰성과 안전성을 철저히 검증해왔습니다. 이 검증 과정은 먹튀 사고를 사전에 차단하기 위한 다단계의 심사 절차로 이루어져 있으며, 바나나 토토가 안정적인 자금 운용 능력을 보유하고 있음을 확실히 증명했습니다. 이러한 검증 결과는 사용자들에게 더욱 신뢰할 수 있는 배팅 환경을 제공하며, 고객들이 안심하고 플랫폼을 이용할 수 있도록 하는 중요한 근거가 됩니다.
바나나 토토는 모든 주요 은행과의 거래를 지원하여, 사용자들이 자신에게 가장 적합한 금융 옵션을 선택할 수 있도록 다양한 선택지를 제공합니다. 이 플랫폼의 금융 시스템은 유연성과 편리성을 갖추고 있어, 고객들이 은행 거래를 더욱 쉽게 처리할 수 있도록 돕습니다. 예를 들어, 사용자는 복잡한 절차 없이 간편하게 자금을 입출금할 수 있으며, 이는 배팅 경험을 더욱 매끄럽고 스트레스 없이 즐길 수 있는 환경을 제공합니다. 이러한 금융 서비스의 포괄적인 지원은 사용자들에게 배팅 외적인 부분에서의 불편함을 최소화하고, 오로지 배팅 자체에만 집중할 수 있는 이상적인 환경을 조성합니다.
고객 지원 서비스는 바나나 토토의 또 다른 강점입니다. 고객센터는 365일 연중무휴로 운영되며, 고객의 편의를 위해 언제나 문을 열고 있습니다. 이곳에는 전문적인 훈련을 받은 상담원들이 상주하며, 고객의 모든 문의와 요청에 대해 친절하고 신속하게 응대할 준비가 되어 있습니다. 고객센터는 단순히 문제를 해결하는 것에 그치지 않고, 고객이 겪을 수 있는 모든 어려움과 불편함을 최소화하는 데 중점을 두고 있습니다. 고객의 문의가 어떠한 것이든 환영하며, 사용자들이 직면할 수 있는 다양한 문제들에 대해 빠르고 효율적인 해결책을 제시하는 것을 목표로 하고 있습니다.
바나나토토를 이용하시면, 철저한 검증을 거친 안전하고 신뢰할 수 있는 배팅 환경에서 최상의 서비스를 경험하실 수 있습니다. 저희는 고객 여러분께 최고의 경험을 제공하기 위해 끊임없이 노력하고 있으며, 고객의 신뢰와 만족을 가장 중요한 가치로 삼고 있습니다. 바나나 토토는 고객들과 함께 성장하며, 앞으로도 지속적으로 더 나은 서비스를 제공하기 위해 최선을 다할 것입니다. 고객 여러분의 성원과 신뢰에 진심으로 감사드리며, 앞으로도 변함없는 지원과 사랑을 부탁드립니다.